High Performance Scala¶
Macros¶
Note
Because scala macros require a separate stage of compilation,
they’ve been broken out into their own package in GeoTrellis.
Otherwise, the functionality to be found there fits most neatly into
geotrellis.raster.
Why Macros?¶
Macros are complex and harder to read than most code. As such, it is reasonable to demand justification when they are employed and to be suspicious of their necessity. Here are some reasons you’ll find macros in GeoTrellis:
Boxing and Unboxing¶
The main purpose for all of the macros employed throughout GeoTrellis
(though mostly in geotrellis.raster) is to avoid the JVM’s so-called
‘boxing’ of primitive types. Boxing, in other contexts, is often called
‘wrapping’ and it involves passing around primitive values (which
normally are lightweight and which require no special setup to work
with) inside objects that are far heavier (a JVM double is 8 bytes while
the boxed variant requires 24 bytes!) and which require processing time
to unwrap.
Readability and Consistency of Performant Code¶
Above, it was pointed out that macros are harder to read. This is true, but there are some special circumstances in which their use can improve readability and help to ensure consistency. When writing performant code, it is often not possible to stay DRY (Don’t Repeat Yourself). This adds significant burdens to future modifications of shared behavior (you have to change code all over the library) and it reduces readability by exploding the sheer amount of text which must be read to make sense of a given portion of code.
How Macros are Used¶
NoData Checks¶
Throughout geotrellis.raster, there are lots of checks about whether
or not a given value is data or whether its value represents NoData.
isData(Int.MinValue) // false
isNoData(Int.MinValue) // true
isData(Double.NaN) // false
isNoData(Double.NaN) // true
This macro provides inlined code which checks to see if a given value is
the GeoTrellis-internal notion of NoData. Int.MinValue and
Double.NaN are the two NoData values Geotrellis isData and
isNoData check against.
Type Conversion¶
Similar to the NoData checks mentioned above, type conversion macros
inline functionality which converts NoData values for different
CellTypes (see the documentation about
celltypes for more on the
different NoData values). This is a boon to performance and it
reduces the lines of code fairly significantly.
Instead of this:
val someValue: Int = ???
val asFloat =
if (someValue == Int.MinValue) Float.NaN
else someValue.toFloat
We can write:
val someValue: Int = ???
val asFloat = i2f(someValue)
Tile Macros¶
Unlike the above macros, tile macros don’t appreciably improve readability. They’ve been introduced merely to overcome shortcomings in certain boxing-behaviors in the scala compiler and understanding their behavior isn’t necessary to read/understand the GeoTrellis codebase.
Micro-Optimizations¶
Loops¶
In Scala “``for`-loops” are more than just loops
<http://docs.scala-lang.org/tutorials/FAQ/yield.html>`__. A commonly-seen
feature throughout the codebase is the use of cfor- or while-loops
where it would seem that an ordinary “for-loop” would be sufficient; we
avoid using them in most cases because the flexibility of Scala’s for
construct can come at a cost.
For example, the following simple for-loop
for(i <- 0 to 100; j <- 0 to 100) { println(i+j) }
does not just just put the value 0 into a couple of variables, execute the loop body, increment the variables and as appropriate, and either branch or fall-through as appropriate. Instead, the Scala compiler generates objects representing the ranges of the outer- and inner-loops, as well as closures representing the interior of each loop. That results in something like this:
(0 to 100).foreach({ x => (0 to 100).foreach({ y => println(x+y) }) })
which can lead to unnecessary allocation and garbage collection. In the
case of more complicated for-loops, the translation rules can even
result in boxing of primitive loop variables.
The cfor construct from the Spire library avoids this problem
because it is translated into the while construct, which does not
incur the same potential performance penalties as the for construct.
Specialization¶
Another strategy that we imply to avoid unnecessary boxing is use of the
@specialized decorator.
An example is the Histogram[T] type, which is used to compute either
integer- or double-valued histograms. The declaration of that type looks
something like this:
abstract trait Histogram[@specialized (Int, Double) T <: AnyVal] { ... }
The @specialized decorator and its two arguments tell the compiler
that it should generate three versions of this trait instead of just
one: Histogram[Int], Histogram[Double] and the customary generic
version Histogram[T]. Although this multiplies the amount of
bytecode associated with this type by roughly a factor of three, it
provides the great advantage of preventing boxing of (most) arguments
and variables of type T. In addition, specialization also opens up
additional opportunities for optimization in circumstances where the
compiler knows that it is dealing with a particular primitive type
instead of a object.
Mutable Types¶
Although use of immutable data structures is preferred in Scala, there
are places in the codebase where mutable data structures have been used
for performance reasons. This pattern frequently manifests as use of
foreach on a collection rather than filter and/or map. This
is helpful because less allocation of intermediate objects reduces
garbage collection pressure.
The Tile Hierarchy¶
One of the most broadly-visible performance-related architectural
features present in GeoTrellis is the tile hierarchy. Prompted by
concerns similar to those which motivated the use of the
@specialized decorator, this hierarchy is designed to prevent
unnecessary boxing. The hierarchy provides a structure of relationships
between tiles of conceptually similar types, for example
IntArrayTiles and DoubleArrayTile, but they are connected via
type-neutral traits rather than traits or base classes with a type
parameter.
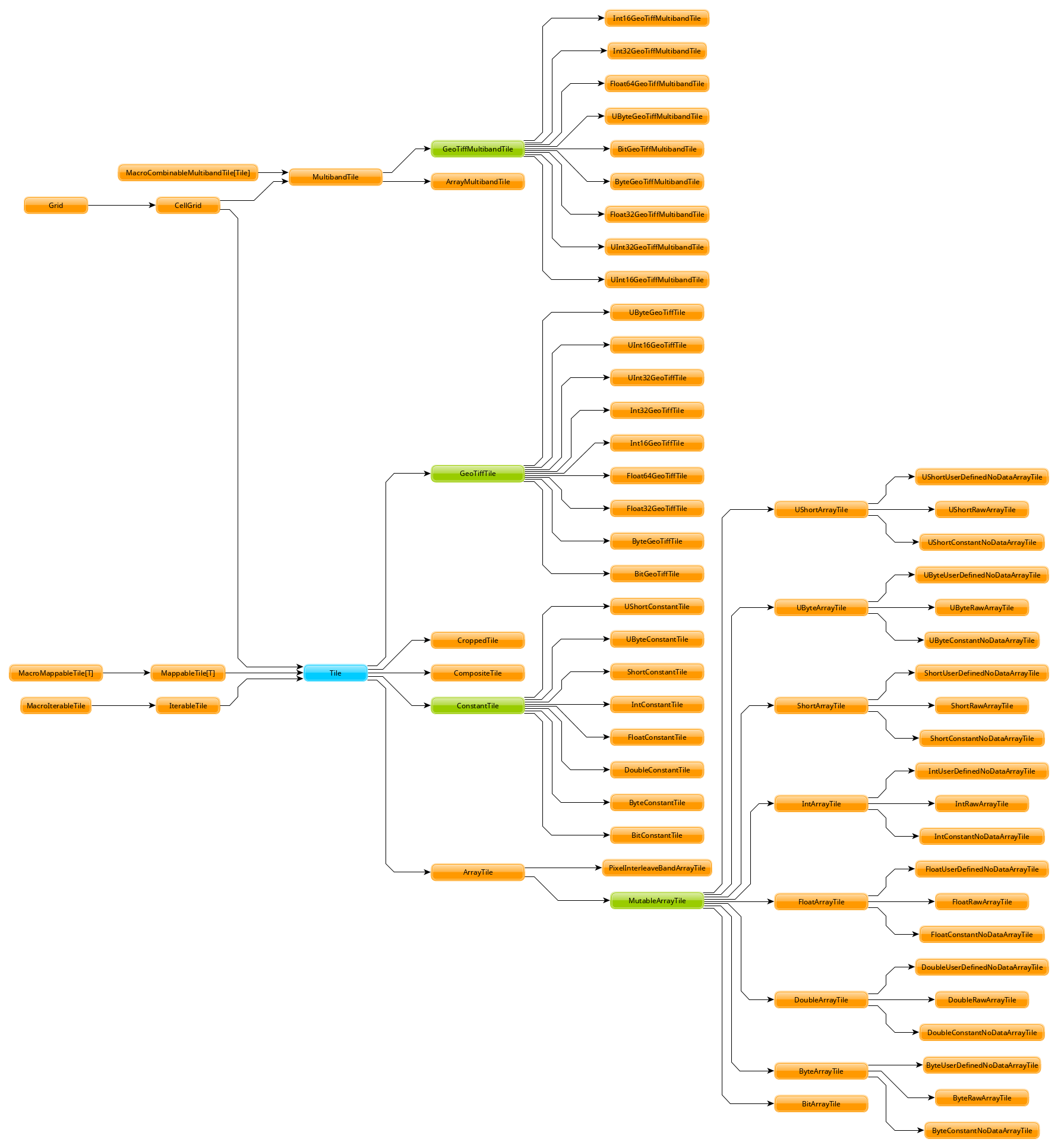
tile-hierarchy
As brief example of the advantage that is provided, the types
IntArrayTile and DoubleArrayTile both share a common ancestor,
ArrayTile, which guarantees that they provide an apply method.
That method is used to index the underlying array. In the case of
IntArrayTile it directly indexes the array and in the case of
DoubleArrayTile the array is indexed and then the retrieved value is
converted form a double to an Int and returned. A reliable
interface is provided, but without the risk of boxing that use of a type
parameter would have.
Along similar lines, the fact that IntArrayTile and
UByteGeoTiffTile share a common ancestor Tile gurantees that
they both provide the method foreach, which allows a function to be
applied to each pixel of a tile. This is possible even though those two
types are backed by very different data structures: an array for the
first one and complex TIFF structure for the second.
Some of the tile-related code is partially-auto generated using Miles
Sabin’s
Boilerplate
mechanism. In particular, this mechanism is used to generate the code
related to TileCombiners.
Spark¶
The two principal Spark-related performance optimizations used throughout the GeoTrellis codebase concern improved serialization performance and avoiding shuffles.
In order to improve serialization performance, we do two things: we use Kryo serialization instead of standard Java serialization and we preregister classes with Kryo.
Kryo serialization is faster and more compact than standard Java serialization. Preregistration of classes with Kryo provides a good performance boost because it reduces the amount of network traffic. When a class is not preregistered with Kryo, that class’ entire name must be transmitted along with the a serialized representation of that type. However when a class is preregistered, an index into the list of preregistered classes can be sent instead of the full name.
In order to reduces shuffles, we prefer aggregateByKey or
reduceByKey over groupByKey as recommended by the Spark
documentations.